
Концепция
Я решил проанализировать базу данных с кино рекомендациями и сделать:
Распределение фильмы по жанрам
Топ 10 лучших фильмов исходя из базы
Топ 10 худших фильмов исходя из базы
Для анализа я использовал
Горизонтальный столбчатый график для отображения распределения количества фильмов по жанрам.
Точечный график для отображения соотношения количества фильмов и жанров.
Вертикальный столбчатый график для топ-10 лучших и худших фильмов.
Для того чтобы вывести топ 10 лучших и худших фильмов из базы я воспользовался ChatGPT
Я попросил его структурировать базу и вывести топ 10.
Код:
import pandas as pd import matplotlib.pyplot as plt
movies_url = «https://raw.githubusercontent.com/jeknov/movieRec/master/movies.csv" ratings_url = «https://raw.githubusercontent.com/jeknov/movieRec/master/ratings.csv"
movies = pd.read_csv (movies_url) ratings = pd.read_csv (ratings_url)
movie_ratings = pd.merge (movies, ratings, on='movieId')
average_ratings = movie_ratings.groupby ('title')['rating'].mean ()
top_10_movies = average_ratings.nlargest (10)
plt.figure (figsize=(12, 8)) top_10_movies.sort_values ().plot (kind='barh', color='skyblue') plt.title ('Топ-10 лучших фильмов') plt.xlabel ('Средний рейтинг') plt.ylabel ('Фильм') plt.show ()
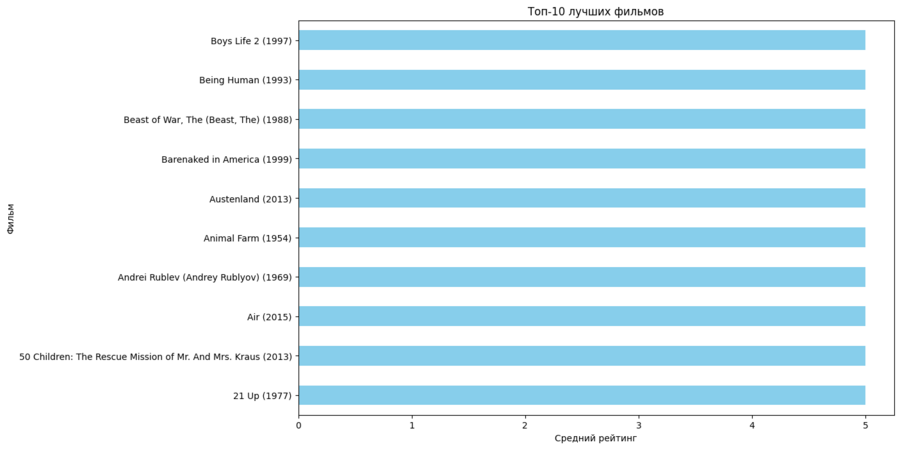
Топ 10 Лучших
Код:
import pandas as pd import matplotlib.pyplot as plt
movies_url = «https://raw.githubusercontent.com/jeknov/movieRec/master/movies.csv" ratings_url = «https://raw.githubusercontent.com/jeknov/movieRec/master/ratings.csv"
movies = pd.read_csv (movies_url) ratings = pd.read_csv (ratings_url)
movie_ratings = pd.merge (movies, ratings, on='movieId')
average_ratings = movie_ratings.groupby ('title')['rating'].mean ()
bottom_10_movies = average_ratings.nsmallest (10)
plt.figure (figsize=(12, 8)) bottom_10_movies.sort_values ().plot (kind='barh', color='lightcoral') plt.title ('Топ-10 худших фильмов') plt.xlabel ('Средний рейтинг') plt.ylabel ('Фильм')
for index, value in enumerate (bottom_10_movies): plt.text (value, index, str (round (value, 2)))
plt.show ()
Топ 10 Худших
Для распределения фильмов по жанрам я обратился за помощью к ChatGPT и попросил его используя данные из базы распределить фильмы по жанрам и визуализировать результат в горизонтальном столбчатом графике.
Код: import pandas as pd import matplotlib.pyplot as plt
url = «https://raw.githubusercontent.com/jeknov/movieRec/master/movies.csv" data = pd.read_csv (url)
genre_counts = data['genres'].str.split ('|', expand=True).stack ().value_counts ()
plt.figure (figsize=(10, 6)) genre_counts.plot (kind='barh') plt.title ('Распределение фильмов по жанрам') plt.xlabel ('Количество фильмов') plt.ylabel ('Жанр') plt.show ()
Так же я сделал точечный график с количеством фильмов определенного жанра.
Исходя из этого графика можно сделать вывод что большим успехом пользуются драматические фильмы. Т.к в формате драмы легче сказать о важных для людей вещах, чем в комедии.
Ссылка на диск с кодом и базой.



