
Этот проект посвящен анализу оценок фильмов, собранных с платформы «Кинопоиск». В рамках работы был проведен разбор данных, очистка, а также визуализация ключевых характеристик, таких как распределение оценок, связь количества рецензий со средней оценкой и выявление лучших и худших фильмов.
Используемые технологии: Python Pandas Matplotlib Seaborn Hugging Face Datasets
Основные задачи проекта Загрузка и предобработка данных (удаление дубликатов, преобразование типов данных). Построение графиков для визуализации оценок фильмов. Анализ взаимосвязи количества рецензий и средней оценки. Определение топ-10 лучших и худших фильмов по средней оценке.
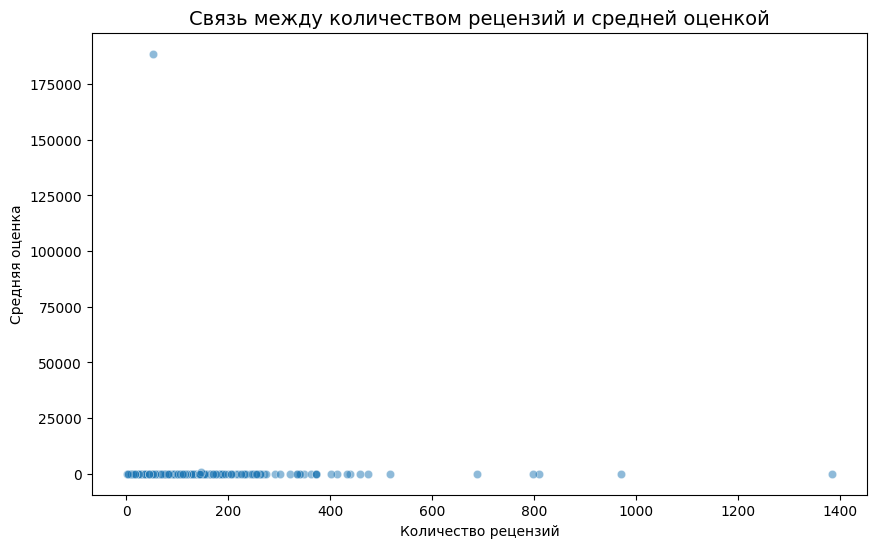
Результаты анализа: Определены топ-10 лучших и худших фильмов. Найдена зависимость между количеством рецензий и средней оценкой.
Данные были выбраны с сайта Kinopoisk, а именно информацию о фильмах, включая названия фильмов, оценки пользователей, количество рецензий и их содержание. Эти данные были получены через библиотеку datasets из репозитория Hugging Face, с использованием датасета blinoff/kinopoisk.
Этапы работы Подготовка данных Сначала я загрузила датасет с помощью библиотеки datasets и преобразовала его в формат pandas DataFrame, что позволило удобно работать с данными. После этого я удалила дубликаты, чтобы избежать некорректных данных, а также преобразовала столбец с оценками (grade10) в числовой формат, чтобы работать с ними в дальнейшем. Агрегация данных Для дальнейшего анализа я сосредоточилась на топ-10 фильмах с наибольшим количеством рецензий и их средними оценками. Для этого я использовала агрегирующие функции value_counts () и groupby (). Визуализация данных Для визуализации я использовала библиотеку seaborn для построения графиков. Я создала графики для анализа.
Код и датасет:



